Physicist: No. But for all practical purposes, yes.
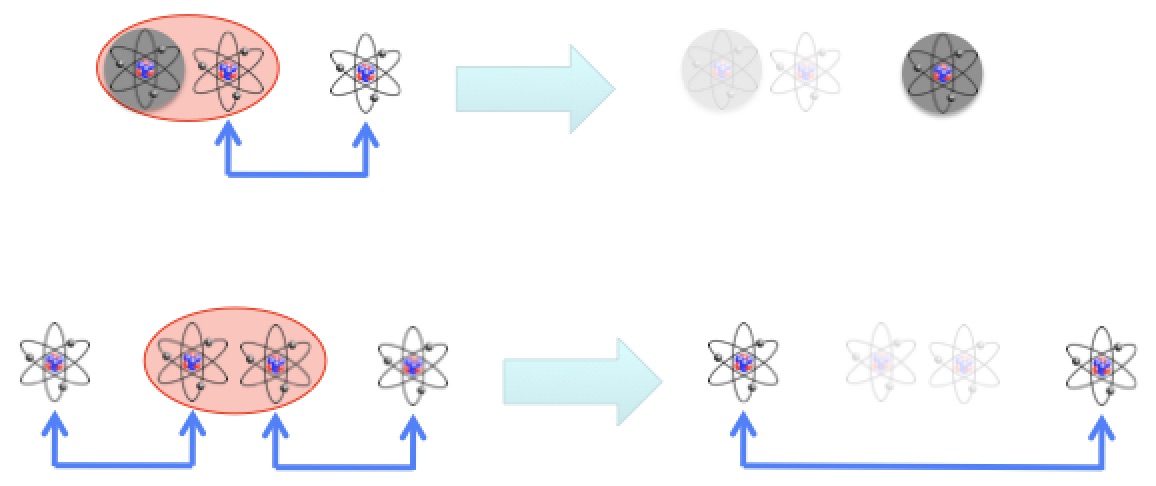
“Fusion” is a pair of atoms coming together and fusing (hence the name) into a single, larger atom. In a chemical bond, like hydrogen and oxygen linking up to form water, the electrons around the nuclei interact with each other. In fusion the nuclei themselves are brought together and in the process a truly fantastic amount of energy is released (for elements lighter than iron). Sadly, it takes some rather extreme circumstances to get nuclei to touch.
As any physicist or marriage counselor can tell you: opposites attract and likes repel. This is about the electrical force on electrical charges and the fact that when you date someone like yourself, you’re dating someone like your least favorite parent. In the nucleus of every atom are positively-charged protons, which packs a lot of positive charge in a very small place and makes it very hard to bring two nuclei together. But if you can get those nuclei close enough, the “nuclear strong force” (so named because it only applies to the stuff inside the nucleus and is, in fact, strong) overwhelms the repulsion and snaps the nuclei together. So the name of the game is getting nuclei close enough for the strong force to take over. But that’s not easy.
To get fusion happening, you get a heck of a lot of hydrogen atoms and just slam them together over and over; the nuclear physics version of winning skeeball with a trash can full of wooden balls. Once hydrogen is heated to above around ten million degrees C, it’s moving fast enough to overcome the repulsive force and very, very occasionally fuse (anyone who’s played around with strong magnets can attest to the fact that if you don’t bring them together square-on, they’ll “slip” off each other and fly apart sideways). The Sun’s core, famously a hotbed of nuclear fusion, is only barely capable of fusion despite its hydrogen being a toasty 15,000,000°C and crushed by the weight of the star above it to twenty times the density of solid iron. The rate of fusion in the Sun is so slow that a person-sized chunk of the core produces heat at about the same rate your body does. The Sun shines because the core is a lot bigger than you, so even that trickle of fusion adds up to a lot. Meanwhile, here on Earth, we use a far more efficient form of fusion.

H-Bombs: briefly more efficient than the Sun.
In fusion weapons we strive to get as much hydrogen to fuse as possible, as quickly as possible, which means temperatures and pressures much greater than the core of the Sun. The “easiest” way to do that is to get a big brick of lithium hydride (which, weirdly enough, has a hydrogen density 50% greater than liquid hydrogen) and surround it with fission bombs to squeeze and heat it. The issue with this method of harnessing fusion power is… existential. An electrical power plant only works when you don’t blow it up. Considering that hydrogen is far and away the most abundant stuff in the universe (and we have oceans of it here on Earth in the form of oceans) and fusion is the greatest potential power source humanity has ever tapped, it would be really nice if we could come up with a way to fuse hydrogen that wasn’t so hot, dense, and explosive. A sort of cold fusion, if you will.
Unfortunately, that’s just not possible with hydrogen. The simple fact is that a pair of free protons zipping around in a plasma (hot hydrogen) are just too good at repelling each other. That colossal heat is necessary for them to get the kind of speed they need to run up the ramp of their mutual repulsive potential and (at least sometimes) get close enough for the strong force to grab them. Ironically, getting close is easier for cold hydrogen gas because each proton carries an electron with it, instead of all of them flying about wildly in a plasma.
A charge looking at a “neutral atom” sees the same amount of positive charge as negative charge, so there’s no net attraction or repulsion for any charges. That balance of charge is, in a nutshell, why you don’t experience literally Earth-shattering electrical forces all the time. Completely strip the electrons from just two grams of matter and place those two grams on opposite sides of Earth, and they’d still be pushing each other so hard you’d need a little over fifty tonnes of force on each to keep them from moving even farther apart. The electric force is bonkers strong and the only reason that matter doesn’t instantly tear itself apart is that all of its charges are perfectly (or very nearly) balanced.
The repulsive force between protons still exists, but only between the nucleus (where all the positive charge is) and the electron cloud that surrounds it (where all the negative charge is). Outside of the electron cloud the positive charge is “shielded” and the electric field is effectively zero; there’s a positive charge and a negative charge right next to it, so they push and pull the same amount in the same direction and cancel each other out.
On the face of it, it would seem that that’s that. If you have neutral hydrogen, then it’s cold and its atoms won’t be slamming into each other hard enough to fuse, and if you have a plasma it needs to be middle-of-a-star hot or hotter. That’s not to say that it can’t be done. There is very active and promising research going on into fusion power, it’s just not cold fusion (and that’s what the question is about).

An active tokamak fusion reactor, using magnets to control and compress plasma. Although systems like this have yet to produce more energy than it takes to run them, they’re getting close. Please note that this is not some sci-fi picture; it’s from a camera pointed through a tiny window into an extremely hot and very unpleasant room.
It just so happens that the electron has a couple of “cousins”, the much heavier muon (~207 electron masses) and the much, much heavier tauon (~3,477 electron masses). Both decay to electrons, but muons take entire millionths of a second to do so (which, for particle physicists, is practically forever).
Muons can orbit atomic nuclei just like electrons do, forming “muonic hydrogen” (for millionths of a second), but their higher mass makes them orbit much closer. This fact is a gorgeous example of the wave nature of matter. As with light, higher energy means higher frequencies and shorter wavelengths. The stable configurations of electrons around an atom are literally standing waves, like the vibration of a guitar string or the ringing of a bell (more precisely, a spherical bell). The closest configuration with the simplest possible harmonic, just one “up and down” of the wave, is the “ground state”. An electron has very little mass, and so very little energy, and so the wavelength is very long (for a particle), and so the ground state is a long way from the nucleus.
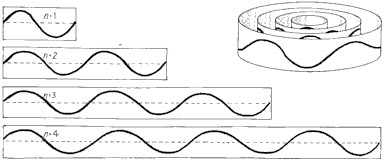
The possible standing waves of an electron determine the possible states it can occupy and how far it stays from the nucleus.
The “Bohr radius”, which is basically the distance between the nucleus and the electron in a hydrogen atom, is given by 


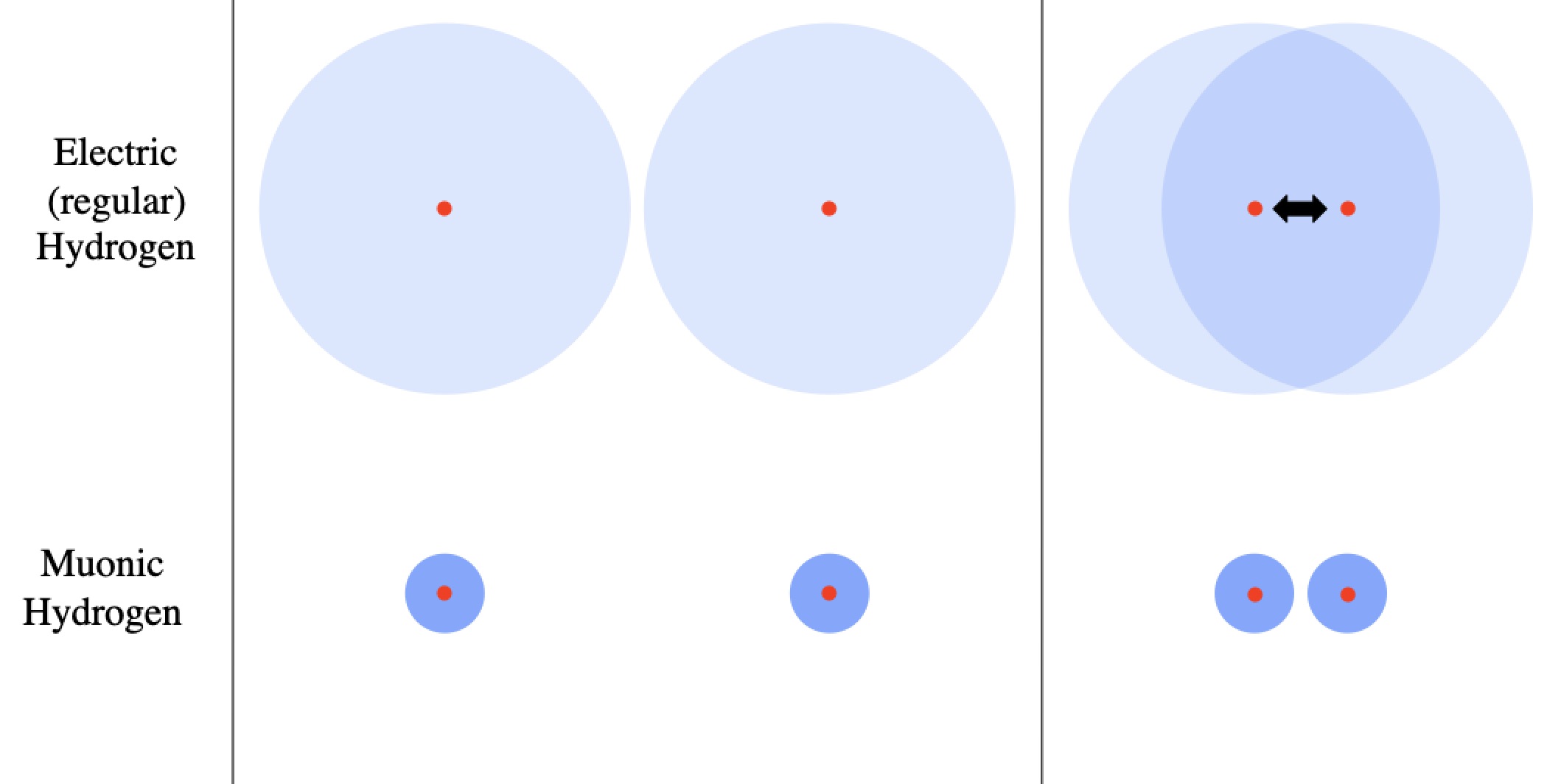
Outside of an atom there’s almost no net pull or push for any protons (or any other charged particle), but once you’re inside the electron shell no longer shields the charge of the nucleus. However, muonic hydrogen is smaller, meaning the repulsive force doesn’t kick in until the atoms are ~200 times closer, meaning it takes less energy to bring the atoms together.
It is so much easier to bring muonic hydrogen together, that it doesn’t even need to be hot to fuse. We can initiate an actual, honest-to-god fusion reaction at below room temperature, which is exactly what cold fusion is supposed to be. Even better, since muons live to such a ripe old age (millionths of a second is a long time compared to the amount of time it takes particles to do practically anything), they can be carried into one fusion reaction, bounce out, form muonic hydrogen with another proton, fuse again, and repeat the process a dozen or so times before finally decaying. So technically, cold fusion is not only possible, but has been done for the better part of a century. The problem is that it’s not useful.
Muons aren’t cheap. Like all fancy particles (“fancy” = “unstable”), to create muons you need enough energy to be released to spontaneously create new particles, some of which may be muons. Being naturally attractive and frugal, undergraduate physicists rely on high-energy cosmic ray interactions in the upper atmosphere to generate muons for their undergraduate projects and just wait for them to rain down into their labs. You’ve been hit by a couple hundred muons a minute for your entire life (more when you’re lying down, because more of you is exposed to the sky). But if you want lots of muons on demand, you need a particle cannon, and particle cannons (as you might imagine) require power. About twice as much power as you can recover from the muon-assisted cold fusion the particle cannon enables, even under ideal conditions.

Cold fusion: it works, but don’t bother.
We’ve had decades to study muon-catalyzed fusion, and so far there’s been very little progress. This may be a fundamental limit, not surpassable by any technology, ever. But, if you’re young, it may be worth your lifetime to find a way to prove that wrong. The beauty of fundamental research is that even if you fail, you’ll figure out some other unexpected stuff along the way.






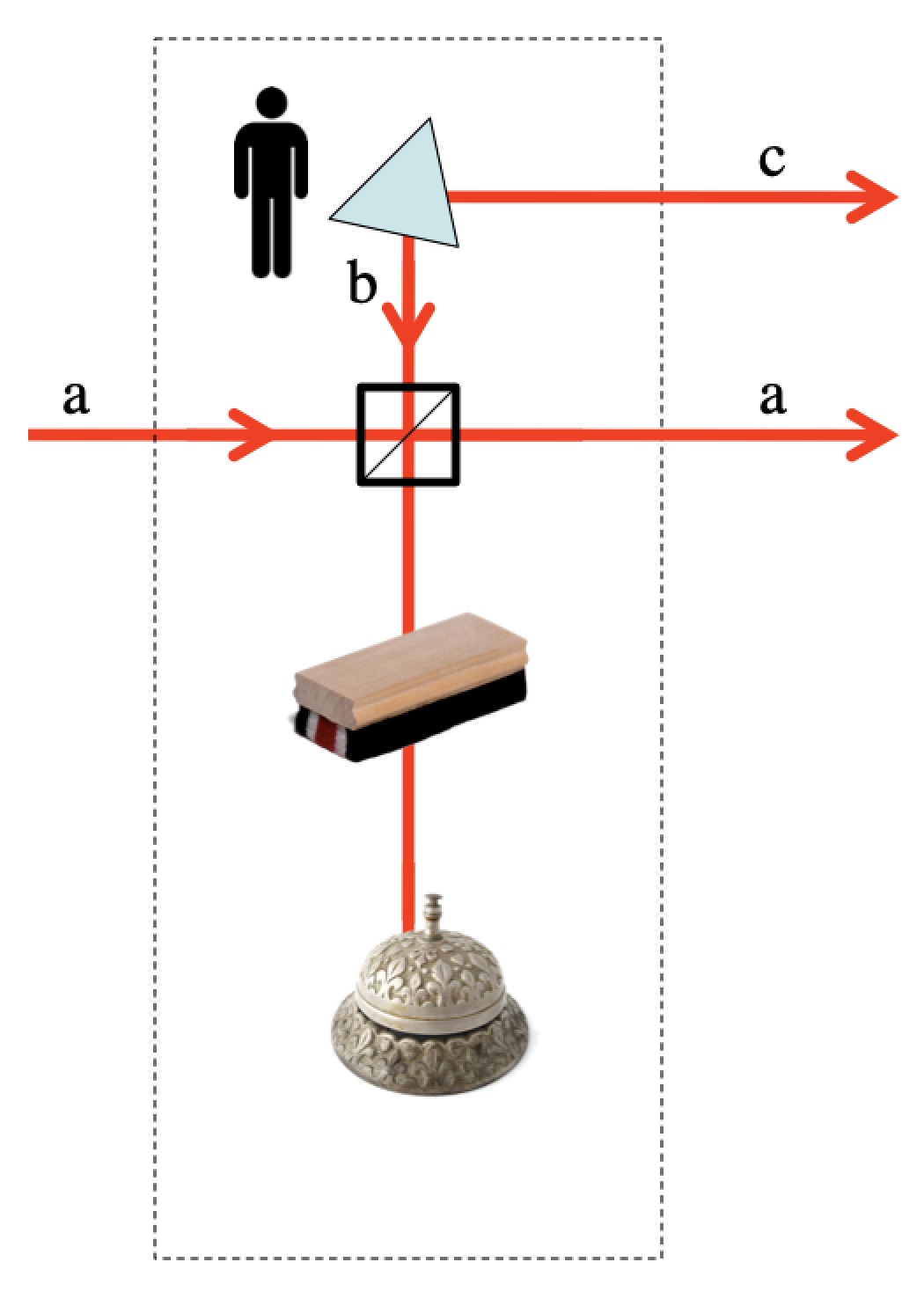
 or
or  , the state of A is verifiably the same before and after passing through the Lab.
, the state of A is verifiably the same before and after passing through the Lab. .
.

 and
and
 . However, if you asked Wigner’s Friend what he experienced, he’d tell you an answer; either vanilla or chocolate, but not both. He doesn’t experience the superposition as anything strange.
. However, if you asked Wigner’s Friend what he experienced, he’d tell you an answer; either vanilla or chocolate, but not both. He doesn’t experience the superposition as anything strange.