The Original Question Was: I have machine … and when I press a button, it shows me one object that it selects randomly. There are enough objects that simply pressing the button until I no longer see new objects is not feasible. Pressing the button a specific number of times, I take a note of each object I’m shown and how many times I’ve seen it. Most of the objects I’ve seen, I’ve seen once, but some I’ve seen several times. With this data, can I make a good guess about the size of the set of objects?
Physicist: It turns out that even if you really stare at how often each object shows up, your estimate for the size of the set never gets much better than a rough guess. It’s like describing where a cloud is; any exact number is silly. “Yonder” is about as accurate as you can expect. That said, there are some cute back-of-the-envelope rules for estimating the sizes of sets witnessed one piece at a time, that can’t be improved upon too much with extra analysis. The name of the game is “have I seen this before?”.

The situation in question.
Zero repeats
It wouldn’t seem like seeing no repeats would give you information, but it does (a little).

How many times do you have to randomly look at cards before they start to look familiar?
The probability of seeing no repeats after randomly drawing K objects out of a set of N total objects is 
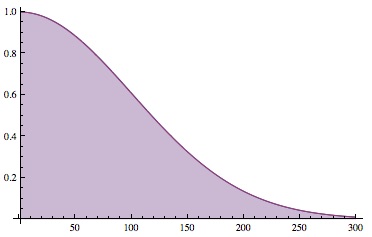
The probability of seeing no repeats after K draws from a set of N=10,000 objects.
The probability is one for K=0 (if you haven’t looked at any objects, you won’t see any repeats), it drops to about 50% for 



Seeing only a handful of repeats allows you to very, very roughly estimate the size of the set (about the square of the number of times you’d drawn when you saw your first repeats, give or take a lot), but getting anywhere close to a good estimate requires seeing an appreciable fraction of the whole.
Some repeats
So, say you’ve seen an appreciable fraction of the whole. This is arguably the simplest scenario. If you’re making your way through a really big set and 60% (for example) of the time you see repeats, then you’ve seen about 60% of the things in the set. That sounds circular, but it’s not quite.

The orbits of 14,000 worrisome objects.
For example, we’re in a paranoia-fueled rush to catalog all of the dangerous space rocks that might hit the Earth. We’ve managed to find at least 90% of the Near Earth Objects that are over a km across and we can make that claim because whenever someone discovers a new one, it’s already old news at least 90% of the time. If you decide to join the effort (which is a thing you can do), then be sure to find at least ten or you probably won’t get to put your name on a new one.
All repeats
There’s no line in the sand where you can suddenly be sure that you’ve seen everything in the set. You’ll find new things less and less often, but it’s impossible to definitively say when you’ve seen the last new thing.

When should you stop looking for something new at the bottom?
I turns out that the probability of having seen all N objects in a set after K draws is approximately 
 - N\ln\left(\ln\left(\frac{1}{P}\right)\right)")
When P is close to zero K is small and when P is close to one K is large. The question is: how big is K when the probability changes? Well, for reasonable values of P (e.g., 0.1<P<0.9) it turns out that \right)")
\ln(N)<K<(N+1)\ln(N)")
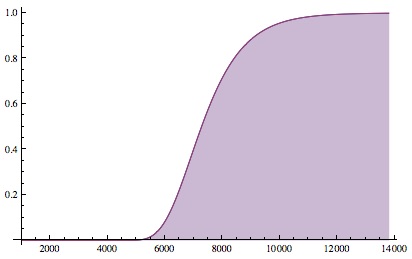
The probability of seeing every one of N=1000 objects at least once after K draws. This ramps up around Nln(N)≈6,900.
So, if you’ve seen N objects and you’ve drawn appreciably more than ")
Answer Gravy: Those approximations are a beautiful triumph of asymptotics. First:the probability of seeing every object.
When you draw from a set over-and-over you generate a sequence. For example, if your set is the alphabet (where N=26), then a typical sequence might be something like “XKXULFQLVDTZAC…”
If you want only the sequences the include every letter at least once, then you start with every sequence (of which there are 
^K")
^K")
^K")
^K")
By the inclusion-exclusion principle, the solution is to just keep flipping sign and ratcheting up the number of missing letters. The number of sequences of K draws that include every letter at least once is ^K}_{\textrm{any but one}}+\underbrace{{N\choose2}(N-2)^K}_{\textrm{any but two}}-\underbrace{{N\choose3}(N-3)^K}_{\textrm{any but three}}\ldots")
^j{N\choose j}(N-j)^K")
![\begin{array}{rcl}P(all) &=& \frac{1}{N^K}\sum_{j=0}^N(-1)^j {N \choose j} (N-j)^K \\[2mm]&=& \sum_{j=0}^N(-1)^j {N \choose j} \left(1-\frac{j}{N}\right)^K \\[2mm]&=& \sum_{j=0}^N(-1)^j {N \choose j} \left[\left(1-\frac{j}{N}\right)^N\right]^\frac{K}{N} \\[2mm]&\approx& \sum_{j=0}^N(-1)^j {N \choose j} e^{-j\frac{K}{N}} \\[2mm]&=& \sum_{j=0}^N {N \choose j} \left(-e^{-\frac{K}{N}}\right)^j \\[2mm]&=& \sum_{j=0}^N {N \choose j} \left(-e^{-\frac{K}{N}}\right)^j 1^{N-j} \\[2mm]&=& \left(1-e^{-\frac{K}{N}}\right)^N \\[2mm]&=& \left(1-\frac{Ne^{-\frac{K}{N}}}{N}\right)^N \\[2mm]&\approx& e^{-Ne^{-\frac{K}{N}}} \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7DP%28all%29+%26%3D%26+%5Cfrac%7B1%7D%7BN%5EK%7D%5Csum_%7Bj%3D0%7D%5EN%28-1%29%5Ej+%7BN+%5Cchoose+j%7D+%28N-j%29%5EK+%5C%5C%5B2mm%5D%26%3D%26+%5Csum_%7Bj%3D0%7D%5EN%28-1%29%5Ej+%7BN+%5Cchoose+j%7D+%5Cleft%281-%5Cfrac%7Bj%7D%7BN%7D%5Cright%29%5EK+%5C%5C%5B2mm%5D%26%3D%26+%5Csum_%7Bj%3D0%7D%5EN%28-1%29%5Ej+%7BN+%5Cchoose+j%7D+%5Cleft%5B%5Cleft%281-%5Cfrac%7Bj%7D%7BN%7D%5Cright%29%5EN%5Cright%5D%5E%5Cfrac%7BK%7D%7BN%7D+%5C%5C%5B2mm%5D%26%5Capprox%26+%5Csum_%7Bj%3D0%7D%5EN%28-1%29%5Ej+%7BN+%5Cchoose+j%7D+e%5E%7B-j%5Cfrac%7BK%7D%7BN%7D%7D+%5C%5C%5B2mm%5D%26%3D%26+%5Csum_%7Bj%3D0%7D%5EN+%7BN+%5Cchoose+j%7D+%5Cleft%28-e%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D%5Cright%29%5Ej+%5C%5C%5B2mm%5D%26%3D%26+%5Csum_%7Bj%3D0%7D%5EN+%7BN+%5Cchoose+j%7D+%5Cleft%28-e%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D%5Cright%29%5Ej+1%5E%7BN-j%7D+%5C%5C%5B2mm%5D%26%3D%26+%5Cleft%281-e%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D%5Cright%29%5EN+%5C%5C%5B2mm%5D%26%3D%26+%5Cleft%281-%5Cfrac%7BNe%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D%7D%7BN%7D%5Cright%29%5EN+%5C%5C%5B2mm%5D%26%5Capprox%26+e%5E%7B-Ne%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D%7D+%5Cend%7Barray%7D&bg=ffffff&fg=000000&s=0 "\begin{array}{rcl}P(all) &=& \frac{1}{N^K}\sum_{j=0}^N(-1)^j {N \choose j} (N-j)^K \\[2mm]&=& \sum_{j=0}^N(-1)^j {N \choose j} \left(1-\frac{j}{N}\right)^K \\[2mm]&=& \sum_{j=0}^N(-1)^j {N \choose j} \left[\left(1-\frac{j}{N}\right)^N\right]^\frac{K}{N} \\[2mm]&\approx& \sum_{j=0}^N(-1)^j {N \choose j} e^{-j\frac{K}{N}} \\[2mm]&=& \sum_{j=0}^N {N \choose j} \left(-e^{-\frac{K}{N}}\right)^j \\[2mm]&=& \sum_{j=0}^N {N \choose j} \left(-e^{-\frac{K}{N}}\right)^j 1^{N-j} \\[2mm]&=& \left(1-e^{-\frac{K}{N}}\right)^N \\[2mm]&=& \left(1-\frac{Ne^{-\frac{K}{N}}}{N}\right)^N \\[2mm]&\approx& e^{-Ne^{-\frac{K}{N}}} \end{array}")
The two approximations are asymptotic and both of the form ^n")
This form is simple enough that we can actually do some algebra and see where the action is.
![\begin{array}{rcl} e^{-Ne^{-\frac{K}{N}}} &\approx& P \\[2mm] -Ne^{-\frac{K}{N}} &\approx& \ln(P) \\[2mm] e^{-\frac{K}{N}} &\approx& -\frac{1}{N}\ln\left(P\right) \\[2mm] e^{-\frac{K}{N}} &\approx& \frac{1}{N}\ln\left(\frac{1}{P}\right) \\[2mm] -\frac{K}{N} &\approx& \ln\left(\frac{1}{N}\ln\left(\frac{1}{P}\right)\right) \\[2mm] -\frac{K}{N} &\approx& -\ln\left(N\right) +\ln\left(\ln\left(\frac{1}{P}\right)\right) \\[2mm] K &\approx& N\ln\left(N\right) - N\ln\left(\ln\left(\frac{1}{P}\right)\right) \\[2mm] \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+e%5E%7B-Ne%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D%7D+%26%5Capprox%26+P+%5C%5C%5B2mm%5D+-Ne%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D+%26%5Capprox%26+%5Cln%28P%29+%5C%5C%5B2mm%5D+e%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D+%26%5Capprox%26+-%5Cfrac%7B1%7D%7BN%7D%5Cln%5Cleft%28P%5Cright%29+%5C%5C%5B2mm%5D+e%5E%7B-%5Cfrac%7BK%7D%7BN%7D%7D+%26%5Capprox%26+%5Cfrac%7B1%7D%7BN%7D%5Cln%5Cleft%28%5Cfrac%7B1%7D%7BP%7D%5Cright%29+%5C%5C%5B2mm%5D+-%5Cfrac%7BK%7D%7BN%7D+%26%5Capprox%26+%5Cln%5Cleft%28%5Cfrac%7B1%7D%7BN%7D%5Cln%5Cleft%28%5Cfrac%7B1%7D%7BP%7D%5Cright%29%5Cright%29+%5C%5C%5B2mm%5D+-%5Cfrac%7BK%7D%7BN%7D+%26%5Capprox%26+-%5Cln%5Cleft%28N%5Cright%29+%2B%5Cln%5Cleft%28%5Cln%5Cleft%28%5Cfrac%7B1%7D%7BP%7D%5Cright%29%5Cright%29+%5C%5C%5B2mm%5D+K+%26%5Capprox%26+N%5Cln%5Cleft%28N%5Cright%29+-+N%5Cln%5Cleft%28%5Cln%5Cleft%28%5Cfrac%7B1%7D%7BP%7D%5Cright%29%5Cright%29+%5C%5C%5B2mm%5D+%5Cend%7Barray%7D&bg=ffffff&fg=000000&s=0 "\begin{array}{rcl} e^{-Ne^{-\frac{K}{N}}} &\approx& P \\[2mm] -Ne^{-\frac{K}{N}} &\approx& \ln(P) \\[2mm] e^{-\frac{K}{N}} &\approx& -\frac{1}{N}\ln\left(P\right) \\[2mm] e^{-\frac{K}{N}} &\approx& \frac{1}{N}\ln\left(\frac{1}{P}\right) \\[2mm] -\frac{K}{N} &\approx& \ln\left(\frac{1}{N}\ln\left(\frac{1}{P}\right)\right) \\[2mm] -\frac{K}{N} &\approx& -\ln\left(N\right) +\ln\left(\ln\left(\frac{1}{P}\right)\right) \\[2mm] K &\approx& N\ln\left(N\right) - N\ln\left(\ln\left(\frac{1}{P}\right)\right) \\[2mm] \end{array}")
Now: the probability of seeing no repeats.
The probability of seeing no repeats on the first draw is 
}{N^2}")
(N-2)}{N^3}")
![\begin{array}{rcl} P(no\,repeats) &=& \frac{N(N-1)\cdots(N-K+1)}{N^K} \\[2mm] &=& 1\left(1-\frac{1}{N}\right)\left(1-\frac{2}{N}\right)\cdots\left(1-\frac{K-1}{N}\right) \\[2mm] &=& \prod_{j=0}^{K-1}\left(1-\frac{j}{N}\right) \\[2mm] \ln(P) &=& \sum_{j=0}^{K-1}\ln\left(1-\frac{j}{N}\right) \\[2mm] &\approx& \sum_{j=0}^{K-1} -\frac{j}{N} \\[2mm] &=& -\frac{1}{N}\sum_{j=0}^{K-1} j \\[2mm] &\approx& -\frac{1}{N}\frac{1}{2}K^2 \\[2mm] &=& -\frac{K^2}{2N} \\[2mm] P &\approx& e^{-\frac{K^2}{2N}} \\[2mm] \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+P%28no%5C%2Crepeats%29+%26%3D%26+%5Cfrac%7BN%28N-1%29%5Ccdots%28N-K%2B1%29%7D%7BN%5EK%7D+%5C%5C%5B2mm%5D+%26%3D%26+1%5Cleft%281-%5Cfrac%7B1%7D%7BN%7D%5Cright%29%5Cleft%281-%5Cfrac%7B2%7D%7BN%7D%5Cright%29%5Ccdots%5Cleft%281-%5Cfrac%7BK-1%7D%7BN%7D%5Cright%29+%5C%5C%5B2mm%5D+%26%3D%26+%5Cprod_%7Bj%3D0%7D%5E%7BK-1%7D%5Cleft%281-%5Cfrac%7Bj%7D%7BN%7D%5Cright%29+%5C%5C%5B2mm%5D+%5Cln%28P%29+%26%3D%26+%5Csum_%7Bj%3D0%7D%5E%7BK-1%7D%5Cln%5Cleft%281-%5Cfrac%7Bj%7D%7BN%7D%5Cright%29+%5C%5C%5B2mm%5D+%26%5Capprox%26+%5Csum_%7Bj%3D0%7D%5E%7BK-1%7D+-%5Cfrac%7Bj%7D%7BN%7D+%5C%5C%5B2mm%5D+%26%3D%26+-%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bj%3D0%7D%5E%7BK-1%7D+j+%5C%5C%5B2mm%5D+%26%5Capprox%26+-%5Cfrac%7B1%7D%7BN%7D%5Cfrac%7B1%7D%7B2%7DK%5E2+%5C%5C%5B2mm%5D+%26%3D%26+-%5Cfrac%7BK%5E2%7D%7B2N%7D+%5C%5C%5B2mm%5D+P+%26%5Capprox%26+e%5E%7B-%5Cfrac%7BK%5E2%7D%7B2N%7D%7D+%5C%5C%5B2mm%5D+%5Cend%7Barray%7D&bg=ffffff&fg=000000&s=0 "\begin{array}{rcl} P(no\,repeats) &=& \frac{N(N-1)\cdots(N-K+1)}{N^K} \\[2mm] &=& 1\left(1-\frac{1}{N}\right)\left(1-\frac{2}{N}\right)\cdots\left(1-\frac{K-1}{N}\right) \\[2mm] &=& \prod_{j=0}^{K-1}\left(1-\frac{j}{N}\right) \\[2mm] \ln(P) &=& \sum_{j=0}^{K-1}\ln\left(1-\frac{j}{N}\right) \\[2mm] &\approx& \sum_{j=0}^{K-1} -\frac{j}{N} \\[2mm] &=& -\frac{1}{N}\sum_{j=0}^{K-1} j \\[2mm] &\approx& -\frac{1}{N}\frac{1}{2}K^2 \\[2mm] &=& -\frac{K^2}{2N} \\[2mm] P &\approx& e^{-\frac{K^2}{2N}} \\[2mm] \end{array}")
The approximations here are \approx x")







This is how biologist estimate populations of things like fish. Capture and tag and release and see how often you capture the same fish twice.
There might be biases, e.g., one biting twice shy.
The “German tank problem” is an interesting twist on this kind of problem.
See: https://en.wikipedia.org/wiki/German_tank_problem
Congratulations! You have been nominated for the Versatile Blogger Award by Coffee & Quasars because they thought your blog was awesome.
Please follow this link to find out more about the award: https://coffeeandquasars.wordpress.com/2016/12/26/versatile-blogger-award/
Anne Chao (1984) came up with a formula that ecologists now use to estimate population size (or species diversity). Chao’s estimator Nc stipulates that N includes some (S0) individuals (or species) that have never been sighted, some (S1) that have been seen just once, some (S2) seen just twice, and maybe some (Sn)with n>2 sightings.
Chao’s formula uses just S1 and S2 to estimate S0 (the number of species NEVER sighted) as
S0 ≈ S1^2 / 2 S2.
That is,
N ≈ Nc = S1^2 / 2S2 + S1 + S2 + …
where Sn = # species observed n times.
The crux of the problem is we don’t know S0, which Chao estimated by the first term in that sum. More compactly, if S is the total number of species ever sighted,
N ≈ Nc = S + (S1^2) / (2*S2).
How precise is the (2-count) Chao Estimator? Its variance (the square of the standard deviation) is:
var(Nc(S1,S2))=
S2*[(r/4)^4 + r^3 + (r/2)^2]
where
r=(S1/S2)
–Generalized S0–
If Sm species are seen m times (and none are seen more): Number of species (including those seen zero times, S0) is
S0+S1+S2+… +Sm, where
S0 ~ D2 = S1^2 / 2 S2
which Chao (2004) generalized, for n in [2,m], to S0 ~
Dn = (S1^n / n! Sn) ^ (1/(n-1)).
ex. 1,0,8;9 -> N~9+(8^3/6)^0.5
=18.2 (best est. when S2=0).
But the numbers seen just once and twice (if any) give the most robust estimate for the number not yet seen:
S0 ≈ S1^2 / 2 S2.
Eample: I’ve plotted successive estimates of the number of active online Scrabble players over the past couple of years. At present, (N2,N1,N) = (28, 485, 519) ——>
Nchao = 4719 ± 778 active players (95% confidence interval).