Physicist: Although there are tricks that work in very specific circumstances, in general when you “encode” any string of digits using fewer digits, you lose some information. That means that when you want to reverse the operation and “decode” what you’ve got, you won’t recover what you started with. What we normally call “compressed information” might more accurately be called “better bookkeeping”.
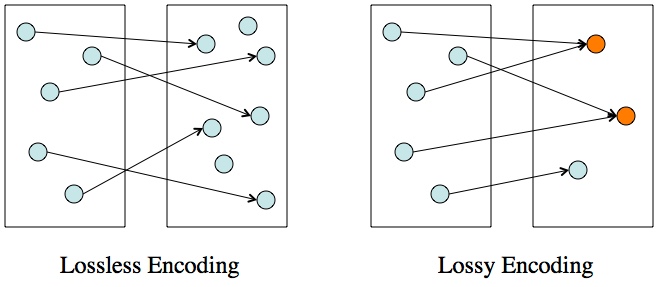
When you encode something, you’re translating all of the symbols in one set into another set. The second set needs to be bigger (left) so that you can reverse the encoding. If there are fewer symbols in the new set (right), then there are at least a few symbols (orange dots) in the new set that represent several symbols in the old set. So, when you try to go back to the old set, it’s impossible to tell which symbol is the right one.
As a general rule of thumb, count up the number of possible symbols (which can be numbers, letters, words, anything really) and make sure that the new set has more. For example, a single letter is one of 26 symbols (A, B, …, Z), a single digit is one of 10 (0, 1, …, 9), and two digits is one of 102=100 (00, 01, …, 99). That means that no matter how hard you try, you can’t encode a letter with a single number, but you can easily do it with 2 (because 10 < 26 < 100). The simplest encoding in this case is a→1, …, z→26, and the decoding is equally straightforward. This particular scheme isn’t terribly efficient (because 27-100 remain unused), but it is “lossless” because you’ll always recover your original letter. No information is lost.
Similarly, the set of every possible twenty-seven letter words has 2627 = 1.6×1038 different permutations in it (from aaaaaaaaaaaaaaaaaaaaaaaaaaa to zzzzzzzzzzzzzzzzzzzzzzzzzzz). So, if you wanted to encode “Honorificabilitudinitatibus” as a number, you’d need at least 39 numerical digits (because 39 is the first number bigger than log10(2627)=38.204).
π gives us a cute example of the impossibility of compressing information. Like effectively all numbers, you can find any number of any length in π (probably). Basically, the digits in π are random enough that if you look for long enough, then you’ll find any number you’re looking for in a “million monkeys on typewriters” sort of way.
So, if every number shows up somewhere in π, it seems reasonable to think that you could save space by giving the address of the number (what digit it starts at) and its length. For example, since π=3.141592653589793238… if your phone number happens to be “415-926-5358“, then you could express it as “10 digits starting at the 2nd” or maybe just “10,2”. But you and your phone number would be extremely lucky. While there are some numbers like this, that can be represented using really short addresses, on average the address is just as long as the number you’re looking for. This website allows you to type in any number to see where it shows up in the first hundred million digits in π. You’ll find that, for example, “1234567” doesn’t appear until the 9470344th digit of π. This seven digit number has a seven digit address, which is absolutely typical.
The exact same thing holds true for any encoding scheme. On average, encoded data takes up just as much room as the original data.
However! It is possible to be clever and some data is inefficiently packaged. You could use 39 digits to encode every word, so that you could handle any string of 27 or fewer letters. But the overwhelming majority of those strings are just noise, so why bother having a way to encode them? Instead you could do something like enumerating all of the approximately 200,000 words in the English dictionary (1=”aardvark”, …., 200000=”zyzzyva”), allowing you to encode any word with only six digits. It’s not that data is being compressed, it’s that we’re doing a better job keeping track of what is and isn’t a word.
What we’ve done here is a special case of actual data “compression”. To encode an entire book as succinctly as possible (without losing information), you’d want to give shorter codes to words you’re likely to see (1=”the”), give longer codes to words you’re unlikely to see (174503=”absquatulate“), and no code for words you’ll never see (“nnnfrfj”).
Every individual thing needs to have its own code, otherwise you can’t decode and information is lost. So this technique of giving the most common things the shortest code is the best you can do as far as compression is concerned. This is literally how information is defined. Following this line of thinking, Claude Shannon derived “Shannon Entropy” which describes the density of information in a string of symbols. The Shannon entropy gives us an absolute minimum to how much space is required for a block of data, regardless of how clever you are about encoding it.
Answer Gravy: There is a limit to cleverness, and in this case it’s Shannon’s “source coding theorem“. In the densest possible data, each symbol shows up about as often as every other and there are no discernible patterns. For example, “0000000001000000” can be compressed a lot, while “0100100101101110” can’t. Shannon showed that the entropy of a string of symbols, sometimes described as the “average surprise per symbol”, tells you how compactly that string can be written.
Incidentally, it’s also a great way to define information, which is exactly what Shannon did in this remarkable (and even fairly accessible) paper.
If the nth symbol in your set shows up with probability Pn, then the entropy in bits (the average number of bits per symbol) is: ")
For example, in that first string of mostly zeros, there are 15 zeros and 1 one. So, 

-\frac{1}{16}\log_2\left(\frac{1}{16}\right)\approx0.337")
In the second, more balanced string, 
-\frac{1}{2}\log_2\left(\frac{1}{2}\right)=\frac{1}{2}+\frac{1}{2}=1")
Here the log was done in base 2, but it doesn’t have to be; if you did the log in base 26, you’d know the average number of letters needed per symbol. In base 2 the entropy is expressed in “bits”, in base e (the natural log) the entropy is expressed in “nats”, and in base π the entropy is in “slices”. Bits are useful because they describe information in how many “yes/no” questions you need, nats are more natural (hence the name) for things like thermodynamic entropy, and slices are useful exclusively for this one joke about π (its utility is debatable).






11 Responses to Q: Is it possible to write a big number using a small number? Is there a limit to how much information can be compressed?